Using Gaussian & GaussView on Tetralith and Sigma
Gaussian is a versatile program for electronic structure modelling.
Homepage: www.gaussian.com
NSC can help you with how to run your Gaussian jobs and to some extend help you with how to set up your Gaussian jobs. We can, for example, help with setting up scripts for running your jobs and help with trouble shooting if you experience issues with running your jobs. If you suspect that you have found a bug in Gaussian, then please contact NSC, so we can investigate and submit a bug report to Gaussian, Inc.
Please contact NSC Support if you have any questions or problems.
Important differences compared with Triolith
These are the most important differences regarding Gaussian compared with Triolith:
- The module names are different
- We use other default settings in the installations
- Specifying Linda parallel jobs are different
- There are no separate modules for GaussView
- Jobs can be submitted directly from GaussView
- There is a command line utility (
sgausbatch) for easy generation and submission of Gaussian run scripts
See the sections below for more details.
Gaussian modules
Use the module avail gaussian command to find available Gaussian installations:
$ module avail Gaussian
-------------------------------------- /software/sse/modules --------------------------------------
Gaussian/recommendation (D) Gaussian/16.B.01-avx2-nsc1-bdist
Gaussian/09.E.01-avx-nsc1-bdist Gaussian/16.C.01-avx2-nsc1-bdist (L)
Where:
L: Module is loaded
D: Default Module
Use "module spider" to find all possible modules.
Use "module keyword key1 key2 ..." to search for all possible modules matching any of the "keys".
Gaussian run scripts from Triolith should also work on Tetralith after the module load line has been updated with a new module name.
Default settings
We use the following default settings for the installations on Tetralith/Sigma:
| Setting | Value |
|---|---|
| -M- (%Mem) | 1GB |
| -P- (%NProcShared) | 1 |
These settings are suitable for small serial (i.e. 1 core) Gaussian jobs. For parallel jobs, you need to explicitly specify %Mem and %NProcShared (or %CPU), as well as %LindaWorkers if you are running large multi-node Gaussian jobs.
Recommendation for specifying memory
Normal Tetralith compute nodes:
cores * 2450 MB
Memory fat Tetralith compute nodes:
cores * 9830 MB
Examples
Example 1 - memory specification for a job using 16 cores on a normal Tetralith compute node:
16 * 2450 MB = 39200 MB
Hence, we get the following Link 0 command settings:
%NProcShared=16
%Mem=39200MB
Example 2 - memory specification for a job using one normal Tetralith compute node (i.e. 32 cores):
32 * 2450 MB = 78400 MB
Link 0 command settings:
%NProcShared=32
%Mem=78400MB
Example 3 - memory specification for a job using one memory fat Tetralith compute node (i.e. 32 cores):
32 * 9830 MB = 314560 MB
Link 0 command settings:
%NProcShared=32
%Mem=314560MB
Linda Parallel jobs
To start Linda parallel jobs, you should now use the %LindaWorkers Link 0 command. This command has the following syntax:
%LindaWorkers=node1[:n1] [,node2[:n2]] …
Where node1, node2, etc. are names of the compute nodes that the Linda workers should run on and n1, n2, etc. are the number of workers to start on respective compute node. However, as you cannot know the real node names when you setup and submit the job, NSC has a run time wrapper that translates a dummy list into a corresponding list with real node names.
Example Link 0 command settings for a Linda parallel job running on two compute nodes:
%LindaWorkers=node1,node2
%NProcShared=32
%Mem=75GB
It doesn’t really matter what you call the nodes in the node list, so just use simple dummy names like node1, node2, etc. What matters is the number of nodes in the list and the number of workers to start for each node. The default is to start one worker per node!
%LindaWorkers list! NSC recommends using one worker per node, but do your own benchmarking to see what works well for your jobs.
%NProcShared setting should not be higher than 32!
%NProcShared vs. %CPU
For Gaussian 16, you can also use the new %CPU Link 0 command, which binds processes to explicit cores. Valid syntaxes:
%CPU=0,1,2,3,4,5
which can also be written as
%CPU=0-5
or, using every second core
%CPU=0,2,4
which can also be written as
%CPU=0-5/2
If your job allocation is less than one whole compute node, then the NSC run time wrapper will change the %CPU core list to the list of actually allocated cores. For example, if you specify %CPU=0,1,2,3,4,5 and allocate six cores for the job, then the NSC run time wrapper will change this list at run time to exactly the cores that were allocated by Slurm for your job.
We have so far not observed any significant performance benefits from using %CPU compared with using %NProcShared, however do your own benchmarking to see if there are any benefits for your jobs.
Starting Gaussian jobs
You can start Gaussian jobs in several ways:
- Directly from GaussView
- From the command line using our utility called
sgausbatch - With your own batch scripts
When using your own batch scripts, please take extra care to always match the sbatch options (e.g. #SBATCH --ntasks) with the Gaussian Link 0 commands (e.g. %NProcShared). One of the common issues we observe for Gaussian jobs is that either too many or too few cores or compute nodes are allocated compared with the Link 0 commands given to Gaussian. For example, a batch script that allocates four whole Tetralith compute nodes with #SBATCH --nodes=4 and then runs a Gaussian job that only sets %NProcShared=32 and no %LindaWorkers command, which then leads to a job that only uses one of the four allocated compute nodes. As these types of mistakes are quite easy to make, we recommend generating your Gaussian batch scripts with the sgausbatch utility, which is developed to help you avoid such mismatch mistakes.
Starting jobs from GaussView
To start GaussView, you should first load a Gaussian module:
$ module load Gaussian/16.C.01-avx2-nsc1-bdist
$ gview
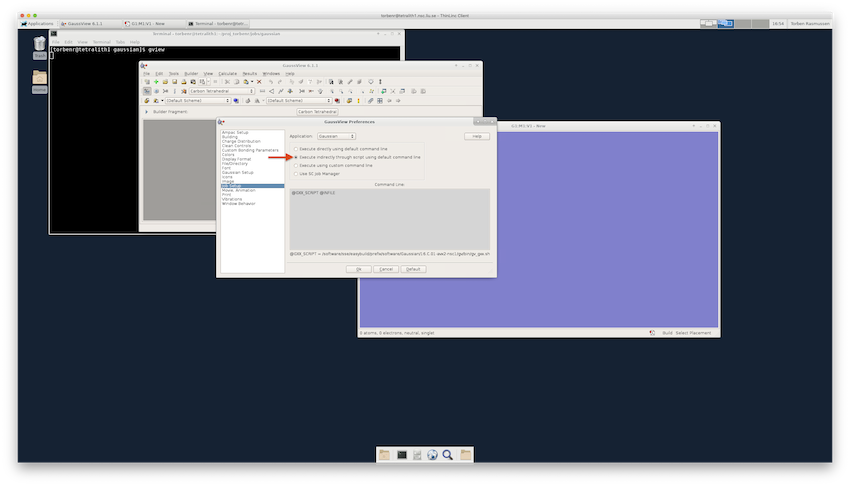
To start jobs from GaussView, you first need to make sure that the “Job Setup” preference is set to “Execute indirectly through script using default command line”. Open the “GaussView Preferences” window (File▸Preferences…) then click on “Job Setup”, choose “Execute indirectly through script using default command line” and click “Ok”.
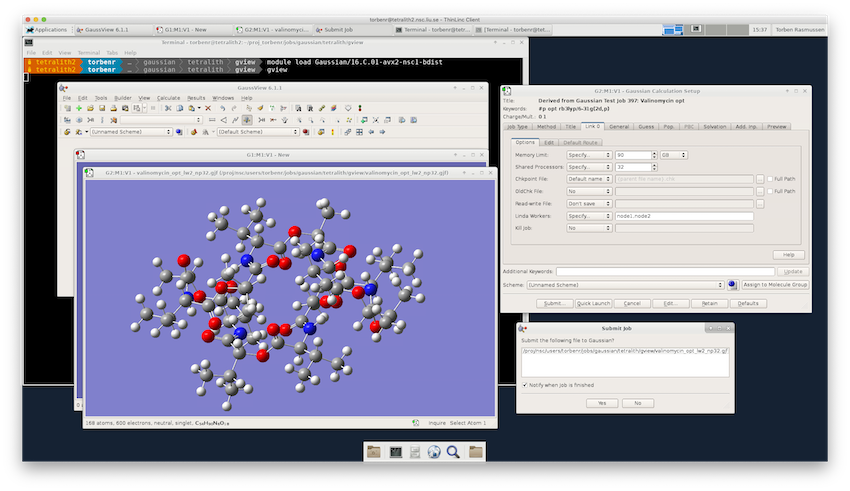
Build a structure or read one in from a file and then open the “Gaussian Calculation Setup” window (Calculate▸Gaussian Calculation Setup…). Once you have chosen the desired specifications and parameters for the job, simply click the “Submit…” button. If you have not already done so, GaussView will ask you to save the input file and then open the “Submit Job” window. Click “Yes” to submit the job.
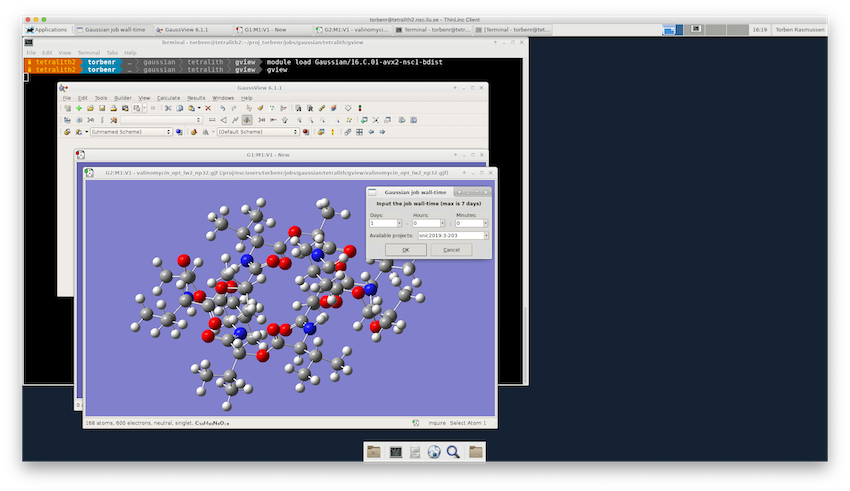
The job then gets submitted to the queue with the sgausbatch utility (see below). When sgausbatch is called from GaussView it launches a small GUI for setting the wall-time for the job as well as the project to charge the core-hours to. Choose the wall-time and project you want for your job and click “OK” to submit the job.
Please see the sections below regarding sgausbatch configuration for instructions that will allow you to control some other settings that you might also like to specify for your jobs. For most use this is not needed, though.
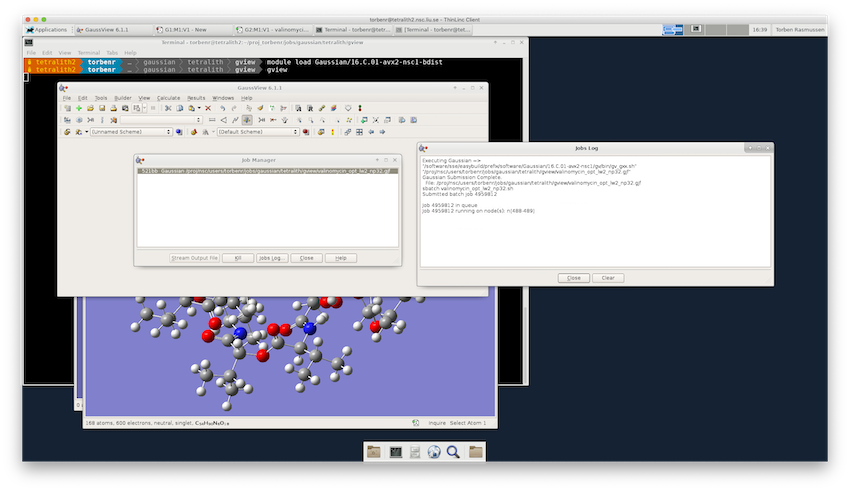
You can check whether the job is queued or running from the “Jobs Log” window, which is opened from the “Job Manager” window that in turn is opened from the “Calculate” menu (Calculate▸Current Jobs…). Unfortunately, the “Jobs Log” window doesn’t update automatically, so to check if there is a change in the job status, you have to close and re-open the “Jobs Log” window. You can, of course, also check the status of the job from the command line in a terminal using the squeue -u $USER command.
Once the job has started, you can stream the output from within GaussView (Results▸Stream Output File). However, it is probably more convenient to follow the progress of a calculation from a terminal using various command line tools.
For geometry optimization jobs, you can read (File▸Open…) the intermediate (or finished) output into GaussView with the option “Read Intermediate Geometries” checked and use that to inspect the progress of the calculation.
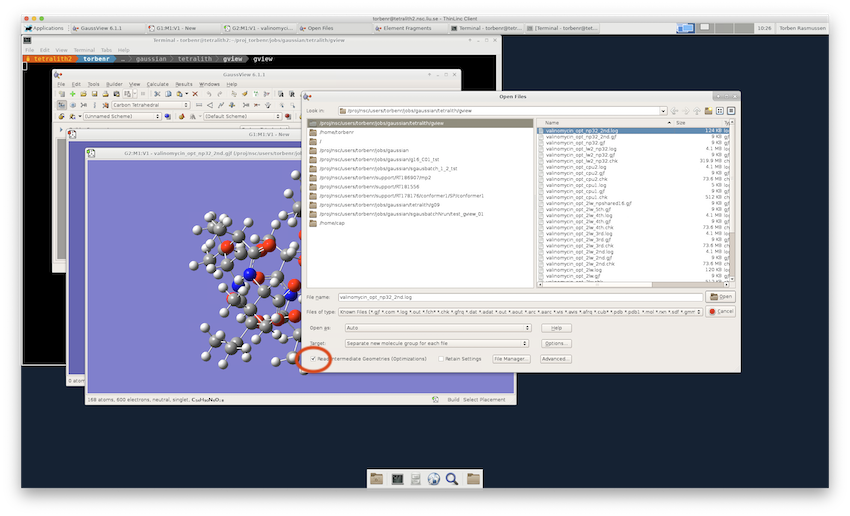
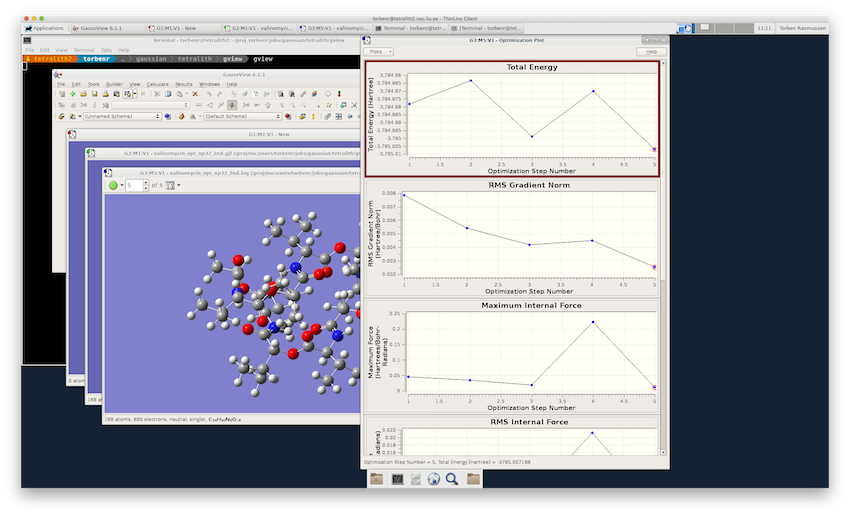
If the job is still running, GaussView will give a warning, but just click “OK” to open the file. You can inspect the progress of the geometry optimization by opening the “Optimization Plot” window (Results▸Optimization…).
Using sgausbatch to submit Gaussian jobs
sgausbatchis an NSC developed command line utility for easy generation and submission of Gaussian run scripts
sgausbatch takes a Gaussian input file and generates a batch script with an appropriate SLURM allocation based on the Link 0 commands in the input. It then automatically submits the job script to the scheduler. If not all required parameters are specified (command line, config file, or sbatch environment variables) sgausbatch will interactively ask for the parameters.
sgausbatch is also used to submit jobs directly from GaussView.
The fundamentals of sgausbatch were developed by Lukas Tallund during a summer internship at NSC in 2014.
Currently developed and maintained by Rickard Armiento and Torben Rasmussen.
For help with using sgausbatch please contact NSC Support. Feedback and feature requests are also welcomed. Please also report all problems, issues, and bugs to NSC Support.
Examples
To get access to sgausbatch, you first need to load a Gaussian module:
$ module load Gaussian/16.C.01-avx2-nsc1-bdist
Then to submit a Gaussian job with default wall-time limit simply do:
$ sgausbatch gaussian_input.com
Note that you will be prompted for the project (SLURM account) to use if multiple such options are available to you.
Command line options
$ sgausbatch --time 1:00:00 gaussian_input.com
The above example will submit the gaussian_input.com Gaussian job to the queue with a wall-time limit of 1 hour.
$ sgausbatch --time 1:00:00 --template myTemplate.sh gaussian_input.com
This example will submit the Gaussian job and generate the job script based on the template myTemplate.sh which must be supplied in the same folder as the gaussian_input.com file. Please see below for more information about the template file.
To see all available command line options, use the -h option:
$ sgausbatch -h
usage: sgausbatch [-h] [-f] [-n] [-o] [-e] [-nt] [-v | -s | -b] [-g] [-t TIME]
[-A ACCOUNT] [-T TEMPLATE] [-J JOBNAME]
FILE [sbatchoptions [sbatchoptions ...]]
Gaussian job submit utility for SLURM.
positional arguments:
FILE Input file to parse.
sbatchoptions Add '--' as flag to set special flags to send to
sbatch in verbatim. Note that this flag must be added
last. Use only if you know what you are doing. e.g.
'-- --reservation=devel'
optional arguments:
-h, --help show this help message and exit
-f, --fatmem Auto-accept the usage of large memory nodes.
-n, --nosub Create run script but do not submit the job to the
scheduler.
-o, --overwrite Overwrite script if file exist.
-e, --exclusive Send exclusive flag to sbatch.
-nt, --notest Do not check gaussian input file with testrt.
-v, --verbose Verbose output.
-s, --silent No output, except required questions.
-b, --batch No interaction. Options not set will be ignored. For
batch scripts.
-g, --gui Launch GUI for setting wall time and account. If used
together with -t and/or -A, then the -t and -A options
will be ignored!
-t TIME, --time TIME Wall time for the job (format: HH:MM:SS). Will be
ignored, if used together with -g. Will use 24:00:00
if not specified.
-A ACCOUNT, --account ACCOUNT
SLURM account that will be used to run the job. If the
account is not valid or not specified you will be
prompted for an account. If only one valid account
exist this will be chosen. Will be ignored, if used
together with -g.
-T TEMPLATE, --template TEMPLATE
Specify a template script file to use. Will use /softw
are/sse/manual/sgausbatchNrun/1.2/resources/sg16batch_
job.sh if not specified.
-J JOBNAME, --jobname JOBNAME
Name that will be used for the job. Will use the file
name of the input file (without suffix) if not
specified.
Configuration file
Values for many options can also be set in a configuration file. This optional user configuration file should be put in your home directory and named sgausbatch_user.cfg. For example, if you always use the same wall time, you can add that to the configuration file. See more information about the configuration file below.
The following format is used in the config file:
[Options]
time=1:00:00
account=snic2017-1-126
...
More Details
sgausbatch parses the Gaussian input file for Link 0 commands and completes a batch script template with appropriate sbatch options. Required options that are not specified on the command line or in the configuration file will be prompted for.
sgausbatch uses the following Link 0 commands in your Gaussian input file to define an appropriate allocation:
%Mem%NProcShared(or%Cpu)%LindaWorkers(or%NprocLinda)
sgausbatch also uses the %Chk command to handle the checkpoint file. With the default template file, defined checkpoint files that exist in the submit directory are copied from submit directory to run directory and from run directory to submit directory.
If a Link 0 command is not set, sgausbatch checks it’s default value in the Default.Route file from the chosen Gaussian module.
Priority of the various ways to set options
When using sgausbatch a number of options can be set. Many options can be set in different ways to make sure you can use the type of setup you prefer. These are the ways to set sgausbatch options:
- command line
- configuration file
- sbatch environment variables (only a subset - not recommended)
Options that are set in several of these places will always be used with the priority listed above. For example, if time is set both on command line and in the configuration file, the command line option will have priority.
Configuration file parameters
The following parameters can be set in the configuration file:
-
account=account_nameSpecifies which SLURM account (i.e. SNIC or LiU project) that should be used for the job.
-
exclusive=False|TrueIf set to
True,sgaubatchwill always send the--exclusiveflag to sbatch. Generally not recommended!Default:
False -
fatmem=False|TrueIf set to
True,sgaubatchwill auto-accept using fat-memory nodes.Default:
False -
jobname=name_of_jobName that will be used for the job. By default the filename of the input file (without suffix) will be used.
-
nosub=False|TrueIf set to
True,sgausbatchwill only generate the batch script, but not submit it to the scheduler.Default:
False -
overwrite=False|TrueIf set to
True,sgausbatchwill overwrite the script file if it already exists, otherwisesgausbatchwill generate a script with the name filename_1.sh.Default:
False -
notest=False|TrueIf set to
True,sgausbatchwill not check the gaussian inputfile with testrt.Default:
False -
template=full_path_to_script_templateSpecifies the template file that will be used to generate the batch script. If not specified, the default template file will be used.
-
time=HH:MM:SSWall time limit for the job.
-
output_mode=verbose|silent|batchverbose: Verbose output.
silent: No output, except questions if needed.
batch: No interaction. Options not set will be ignored. Intended for use in batch scripts.
-
sbatchoptions=blank separated list of sbatch optionsList extra sbatch options to include in the job script. Generally not needed unless you want to use a specific reservation.
Examples
Set a default for job wall time and project to use for the job allocation:
[Options]
account=snic2017-1-126
time=10:00:00
Note that setting the account to use for a job allocation is only needed if you are included in several projects.
Use your own batch script template:
[Options]
account=snic2017-1-126
time=10:00:00
template=/proj/snic2017-1-126/users/username/jobs/gausjobtemplates/batchjobtemplate_std.sh
Add a few more sbatch options to the job batch script:
[Options]
account=snic2017-1-126
time=10:00:00
template=/proj/snic2017-1-126/users/username/jobs/gausjobtemplates/batchjobtemplate_std.sh
sbatchoptions=--mail-type=END,FAIL --mail-user=user@university.se
Note that sbatch options can also be added by editing the batch script template.
SBATCH environment variables
sgausbatch will check and use these sbatch environment variables, but they have lower priority than command line options and options set in the user configuration file:
SBATCH_ACCOUNTSBATCH_EXCLUSIVESBATCH_JOBNAMESBATCH_TIMELIMIT
Script template file
Default batch script template file used by sgausbatch:
#!/bin/bash
<%doc>
This is a template for running Gaussian calculations using the sgausbatch utility.
The template can be copied and edited, but this is not recomended unless you are very familiar
with running Gaussian jobs on a cluster and well versed in sbatch options. Point to your own version
of the template with the command line option --template or equivalent configutation option.
Here is a list of variables that can be used in the template:
${account} - The account used for the calculation (e.g. specfied with the -A flag).
${chkname} - Name of the checkpoint file.
${chkpath} - Path of the checkpoint file.
${constraint} - Which node type to use (e.g. fat).
${exclusive} - The exclusive option is used.
${filenamenosuffix} - Name of the input file without suffix.
${filename} - Full name of the input file.
${filesuffix} - The suffix of the input file.
${gausversion} - Gaussian module to use.
${jobname} - The name of the job (e.g. specified with the -J flag). Same as filenamenosuffix if not specified.
${memory} - The memory allocation in MB used by the Gaussian job.
${nproclinda} - Number of Linda workers that will be used.
${nprocshared} - Number of threads each Linda worker will use.
${sbatchoptions} - Items given to the -- flag.
${summary} - A summary of the parameters used by sgausbatch.
${time} - Wall time limit for the calculation (e.g. specified with the -t flag).
${workdir} - The work-directory for the calculation.
${nodes} - Number of compute nodes that will be used.
${lindapernode} - The number of Linda workers per node.
${gaussianbin} - Name of gaussian binary.
${nodemaxthreads} - Max number of threads on selected nodetype.
${nprocpernode} - lindapernode * nprocshared.
</%doc>
# User provided sbatch options can be added here
# sbatch options set by sgausbatch
#SBATCH --account=${account}
% if not constraint=="thin":
#SBATCH --constraint=${constraint}
% endif
#SBATCH --cpus-per-task=${nprocshared}
% if exclusive:
#SBATCH --exclusive
% endif
#SBATCH --ntasks-per-node=${lindapernode}
#SBATCH --job-name=${jobname}
#SBATCH --nodes=${nodes}
#SBATCH --time=${time}
% if not sbatchoptions==None:
#SBATCH ${sbatchoptions}
% endif
<%doc>
Ensure that we only restrict the memory of the slurm allocation for jobs on shared nodes
</%doc>
% if not exclusive and nprocpernode < nodemaxthreads and nodes==1:
#SBATCH --mem=${memory+512}
% endif
# Load the Gaussian module
module load ${gausversion}
cd $GAUSS_SCRDIR
% if chkpath=="" and not chkname=="":
# Trap SIGTERM and copy the chk file if the job hits the walltime limit
trap 'if [ -f ${chkname} ]; then cp ${chkname} ${workdir}; else echo "No named chk file"; fi; echo "SIGTERM was trapped"' SIGTERM
if [ -f ${workdir}/${chkname} ]
then
cp ${workdir}/${chkname} .
fi
% endif
${gaussianbin} < ${workdir}/${filename} > ${workdir}/${filenamenosuffix}.log &
wait
g_exit_status=$?
% if chkpath=="" and not chkname=="":
if [ -f ${chkname} ]
then
cp ${chkname} ${workdir}
fi
% endif
exit $g_exit_status
# Summary of parameters used by sgausbatch
${summary}
# END OF SCRIPT
The script template is based on Mako Templates for Python, so look at that if you want to make substantial changes.
 User Area
User Area

